Context
The service you are developing provides APIs for users. When an user calls an API, (s)he must show a short-living authorization credential, e.g. an OAuth2 token.
The user creates, owns, updates or deletes resources in the service on behalf of the account to which the credential is associated. Here, the `user' might be (an user-agent operated by) a human but also it might be an automated program running in background.
Also you want to use captcha to prevent huge number of accounts from being registered for some fraud purpose.
And you might even want to let users register their billing address for charging.
Problem
It is hard for users to securely manage accounts which automated programs use.
"manage" here basically means to create/update credentials as necessary and handle bills. A human (or a specialized billing-system, at least) must handle these things instead of the automated program because such a program tends to be bad at solving captcha -- it is by design and raison d'être of captcha --, and it is even worse at receiving bills by mail and going to bank to pay.
Then, how can (s)he manage the account for the program? Although some easy solutions come to the mind of the user, they do not work fine enough.
Reuse the account of the human for the program
Individual members in the team which manage the program can leave the team.
So suppose that the owner of the account leaves the team. Then the resources owned by the person can be deleted, or access to the resources can be restricted. At least, it would get hard to manage authentication credentials of the account.
Create an account only for the program
In this approach, (s)he creates a new account for the program in the same way as (s)he creates an account for human. Then the person lets the program use the new account. This account is shared by the team. So even if someone leaves the team, someone else in the team can manage the account.
There are, however, some scenarios in which this approach will not work fine. First, members in the team must share the authentication credential, e.g. passwords, to manage the account. But it is hard to track usage of the credential for audit. Second, even though it would get harder to keep the authentication credential secret as the team gets larger and the team needs to update the credential when necessary, it would also get harder to notify the update to all members in the team. Finally, even if they solve the issues above, it still tends to happen that someone in the team creates an account but (s)he leaves the team without sharing the account with others. Then none can manage the account.
To make things worse, they need to keep the account for the program having the minimum rights for security. It means that they will have more number of accounts per usage and the issues above becomes more serious.
Examples
1. Github - Travis integration
System
Resource
private repositories
Account
github account
short-living authorization credential
OAuth2 token issued by github
Authentication information to manage the account
Password of the github account
Automated Program
Build processes running on Travis CI.
2. Cookpad - AWS
System
Resource
S3 bucket
Account
AWS account
short-living authorization credential
Authentication information to manage the account
AWS password
Authomated program
The feature that allows users of Cookpad to upload their pictures of dishes.
Solution
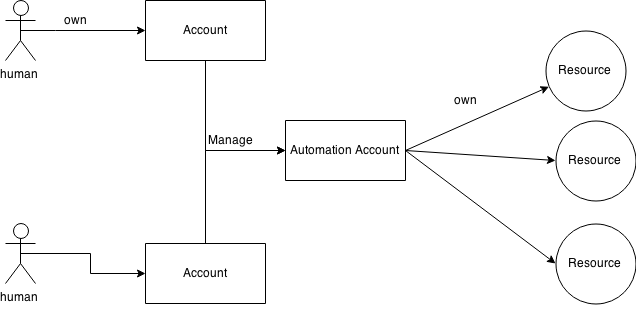
Define another kind of accounts ( Automation Account ), which is only for automated programs.
Distinguish this kind of accounts from ordinal accounts for humans.
Do not assign any passwords to automation accounts. Instead, associate the automation account to a list of human accounts who can manage the automation account.
Humans in the list just need to login to the system with their own human accounts when they manage the automation account. So they don't need to share the password of the automation account. Moreover, the automation account does not need to have its own password.
Implementatinos
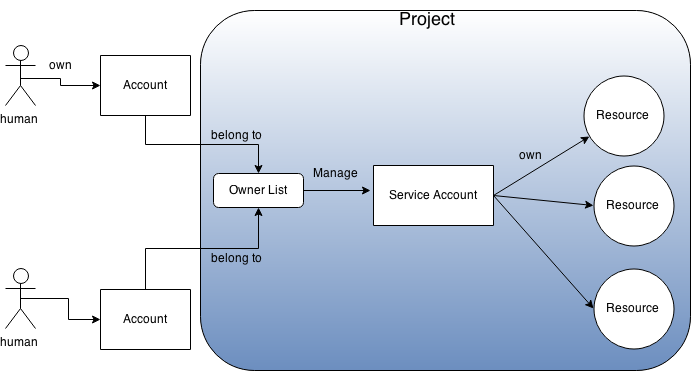
1. Service Accounts in Google Cloud Platform (GCP)
- Most of resources provided by APIs in GCP belong to a unit called "project".
There are two kinds of accounts: ordinal (human) accounts and service accounts
- User accounts for humans (Gmail accounts or accounts of Google Apps for Work) are independent from projects, and those accounts can join arbitrary number of projects as read-only, writable or owners.
- On the other hand, service accounts are accounts only for automated programs. A service account uniquely belongs to a project. And when the project is deleted, the service account is also deleted together with other resources in the project.
Since service accounts do not have passwords for login, you can not use service accounts when you log into web pages but you can use them only for API calls with their OAuth2 tokens. Also you have to use your own human account and the the account must be an owner of the project when you manage the service account.
- Billing information is registered per project. Any operations on resources in a project are charged to the billing information of the project.
2. AWS Identity and Access Management (IAM)
- Resources provided by APIs in AWS belong to an AWS user account (root account).
You can create arbitrary number of IAM accounts under the root account.
- You can assign an IAM account to human, but also you can assign an IAM account to an automated program without giving any password to the account.
You have to use the root account or an IAM account for human when you need to login to the web console to manage IAM accounts.
- Billing information is registered per root account. Any operations done by IAM accounts are charged to their root accounts.

Let's compare the two implementations.
The approach of GCP is a bit more complicated for hobby developers because GCP requires the developer to create a "project" in addition to his/her human account even though (s)he is the only developer in the development team. On the other hand, (s)he would be able to do everything just with his/her root accounts in AWS.
Next, let's think about larger development projects. AWS is a bit less secure because root account itself is an account with username and password and the dev team must keep the account secure in addition to their IAM accounts. On the other hand, GCP is secure because it does not have this kind of extra authentication credential which is not usually used.