コンテキスト
あなたが開発しているサービスはユーザー向けにAPIを提供している。そして、APIを利用するにはユーザーは短寿命の認可情報(たとえばOAuth2トークン)を提示しなければならない。
ユーザーは認可情報が紐付いているアカウントの権限でリソースを読み取ったり、作成したり、所有したり、編集または削除したりする。 ここで、ユーザーは人間(が操作するユーザーエージェント)であることもあるが、人間の手を離れてバックグラウンドで自動実行されるプログラムかもしれない。
また、あなたは悪用目的でアカウントが大量登録されるのを防ぐためにCaptchaを利用したいと思っている。 さらに、課金目的で請求書送付先を登録させたいとも思っているかもしれない。
問題
プログラムが利用するアカウントを安全に管理するのがユーザーにとって困難である。
プログラムは自分でCaptchaを解いたりEメールを受け取るのが苦手だし(そうでないとCaptchaの意味がない)、 また郵便物で請求書を受け取って銀行に振り込みに行くのは更に苦手である。 よって、プログラムが利用するアカウントを作成し、管理し、対応する請求書を処理するのは人間(か、少なくともそれ専用の別のシステム)でなければならない。
ではその人間はどのようにそのプログラムが利用するアカウントを管理すれば良いのか。幾つかの簡単な解決策を思いつくが、いずれも十分とは言えない。
人間のアカウントを使い回す
プログラムを管理しているチームの誰かのアカウントを使う、という解決法。
しかし、個々の人間は自動プログラムを管理ししているチームを離れることがある。このアカウントを所有していた人物がいなくなると、 アカウントの元に所有されていたリソースは消滅したり、アクセスが制限されたりする可能性がある。 最低でも、そのアカウントの認可情報を更新するのは困難となる。
プログラム専用のアカウントを共有する
人間用のアカウントを作るのと同様にして、人間がプログラム専用のアカウントを作成する。そしてそのアカウントをプログラムに利用させる、という解決法。 アカウントは自動プログラムを管理する人間たちによって共有されており、たとえ誰かがチームから居なくなっても 他の者がアカウントの管理、認可情報の更新などを行える。
しかし、これもまた十分とは言えない。人間たちはアカウントを管理するためのパスワードなどの認証情報を共有しなければならないが、 その周知の情報をいつ誰が利用したのか監査記録を付けるのは大きなチームでは難しい。 また大きくなるほど認証情報漏洩のリスクは高まって適時の更新が必要とされるが、大きくなるほど更新したという事実を全員に伝えるのも難しい。 苦労してこれらの問題を解決したところで、誰かが開発用にアカウントを作ったが良いが周知するのを忘れたままチームを去って、結局誰も管理できないアカウントになったりするのもありがちな問題である。
更に、セキュリティ上はプログラム専用アカウントは最小限の権限を持つのが望ましいが、最小化するために権限ごとにアカウントを設定すると 管理すべきアカウントの数が増えて管理にまつわる問題は酷くなっていく。
具体例
1. Github - Travis連携
システム
リソース
プライベートリポジトリ
アカウント
githubアカウント
短寿命認可情報
githubのOAuth2 token
管理のための認証情報
githubのパスワード
自動化プログラム
travisによるビルドプロセス
2. クックパッド - AWS
解決策
自動化プログラム用のアカウント種別(Automation Account)を作って、人間用のアカウントとは区別する。 また、Automation Accountには管理用のパスワードを割り当てず、代わりに「このAutomation Accountを管理できる人間用アカウントのリスト」を対応させておく。
人間たちは自分自身の人間用アカウントでログインするだけで(リストに載っていれば)Automation Accountを管理できる。 このため、Automation Accountのパスワードを共有する必要はない。 それどころか、プログラム用のアカウントはどうせ人間の誰かが自分のアカウントで管理するのだからAutomation Accountにはパスワードがなくても差し支えない。
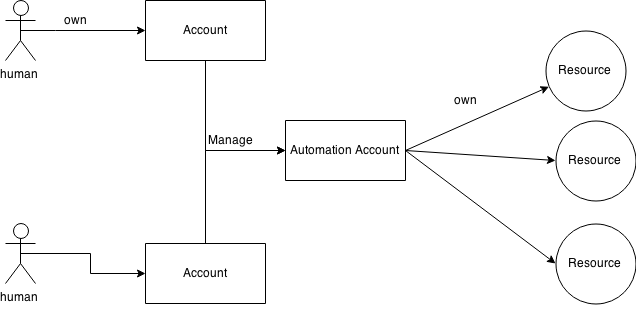
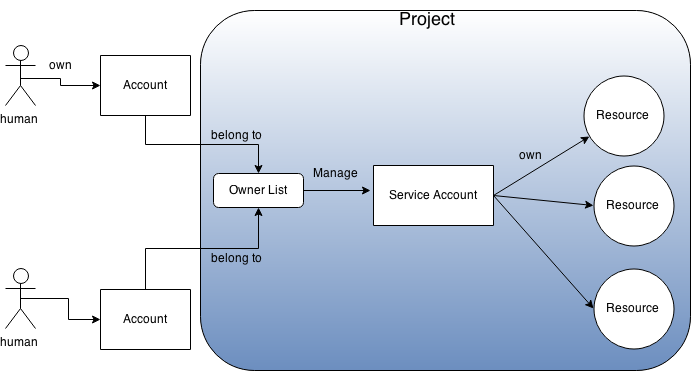
実現例
1. Google Cloud Platform (GCP)のサービスアカウント
GCPのAPIが提供するほとんどのリソースは「プロジェクト」という単位に所属する。
ユーザーアカウントはプロジェクトとは独立したアカウント(GmailアカウントまたはGoogle Apps for Workアカウント)で、 任意の数のプロジェクトに読み取り専用、書き込み可、またはオーナーとして参加できる。
これに対してサービスアカウントはプログラム専用のアカウントで、ただ1つのプロジェクトに一意に属し、プロジェクトが削除されると他のリソースと同様サービスアカウントも削除される。
サービスアカウントはログイン用のパスワードを持たないためWebページのログインには利用できず、OAuth2トークンを用いてプログラムからAPIを呼ぶためにしか利用できない。 サービスアカウントを管理するには、そのプロジェクトのオーナーになっている人間のアカウントを利用する。
課金先情報はプロジェクトごとに登録管理される。サービスアカウントであれ一般のユーザーアカウントであれ、プロジェクト内のリソースに対する操作はプロジェクトに対して課金される。
2. AWS Identity and Access Management (IAM)
APIが提供するリソースは特定のAWSユーザーアカウント(rootアカウント)に属する。
権限を分割するために、ユーザーアカウント内に任意個のIAMアカウントを作成できる。 IAMアカウントはパスワードを設定して人間に割り振ることもできるし、パスワードを与えないでおいてプログラムに利用させることもできる。 プログラム用のIAMアカウントを管理するためにwebコンソールにアクセスする場合は、パスワードを割り振られた人間用のIAMアカウントまたはrootアカウントを利用する。
課金情報はrootアカウントごとに登録管理される。IAMアカウントが利用したリソースはその属するrootアカウントに対して課金される。

2つの実現例を比べてみよう。
GCPのアプローチは一個人が趣味で開発しているような小規模開発においても、開発者のアカウントの他にプロジェクトという単位を作成する必要があるのでやや煩雑である。 一方AWSのアプローチは個人の小規模開発であれば人間用にはIAMアカウントを発行せず、rootアカウントだけですべてを済ませることも可能なので単純である。
大規模な場合に目を移すと、AWSのアプローチはrootアカウントそれ自体がユーザー名とパスワードを持つアカウントであるため、守るべき対象が1つ多い分だけほんの少しセキュアでない。 またそもそもこのrootアカウントのパスワードをどう管理するかという点において上記と類似の問題が残されたままである。 これに対してGCPでは、この通常使われることのない余分な認証情報はそもそも存在しないのでセキュアである。